La perplejidad es una medida estadística de cuán confiadamente un modelo de lenguaje pre entrenado predice un texto. En otras palabras, la perplejidad cuantifica qué tan «sorprendido» está el modelo cuando ve nuevos datos. Cuanto menor sea la perplejidad, mejor será el modelo en predecir el texto (o el texto está más relacionado con el corpus con el cual se entrenó el modelo).
En el siguiente ejemplo se usa el modelo pre entrenado “dmis-lab/biobert-base-cased-v1.2” para calcular la perplejidad de textos, y luego identificar cuál de ellas está más relacionada con temas biomédicos.
Estos son algunos posibles escenarios donde la perplejidad puede ser útil:
Limpieza de datos para identificar textos relacionados o no con área específica.
Evaluar la fluidez y coherencia del texto generado.
Detección de oraciones anómalas o atípicas dentro del conjunto de dato. Oraciones con una perplejidad inusualmente alta podrían sugerir errores o incoherencias en el texto.
-
Detectar errores gramaticales o terminológicos en el texto que necesitan corrección.
En este script (Python) se calcula la pérdida (loss) de las predicciones del modelo para el texto dado, y después se calcula la perplejidad utilizando la fórmula exp(loss / num_tokens).
El modelo “dmis-lab/biobert-base-cased-v1.2” está disponible en la plataforma Huggins Face y se descarga a través de la librería Transformer. (ver script python)
Example of Sentence Perplexity with Biomedical Language Model¶
This notebook explore sentence perplexity using the PerplexityCalculator class, which leverages the dmis-lab/biobert-base-cased-v1.2 pre-trained model. This notebook analyzes perplexity across a set of sample sentences and provides insights into the intricate nature of language modeling within the biomedical domain.
import pandas as pd
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
pd.set_option('display.max_colwidth', None)
class PerplexityCalculator:
def __init__(self, model_name="dmis-lab/biobert-base-cased-v1.2"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForMaskedLM.from_pretrained(model_name)
def calculate_perplexity(self, sentence):
tokens = self.tokenizer.encode_plus(sentence, add_special_tokens=True, return_tensors="pt")
input_ids = tokens['input_ids']
with torch.no_grad():
outputs = self.model(input_ids, labels=input_ids)
loss = outputs.loss
num_tokens = input_ids.size(1)
perplexity = torch.exp(loss / num_tokens)
return perplexity.item()
sentences = [
# 5 questions with content highly related to medical health
"What does a new study show about the vaccine's effectiveness in reducing the risk of infection?",
"What symptoms did the patient exhibit consistent with the flu, and what was done immediately?",
"What does the research paper discuss regarding the efficacy of a novel drug in treating cancer?",
"What complex neurosurgery did the medical team successfully perform on the infected patient?",
"How can physical therapy and regular exercise improve joint mobility in arthritis patients?",
# 5 questions with content slightly related to medical health
"What topics were covered in the conference related to healthcare and wellness?",
"Why did she decide to take up yoga and how does it improve her overall well-being?",
"What benefits are highlighted in the article regarding a balanced diet and maintaining good health?",
"Why is regular handwashing essential in preventing the spread of infections?",
"What did the documentary focus on regarding the impact of pollution on public health?",
# 5 questions with content non-related to medical health
"How has the new movie release been received by critics?",
"What was the outcome of the championship game for the team?",
"What does she enjoy doing in her free time, specifically related to reading?",
"What did the company announce regarding the launch of their latest smartphone?",
"What does the weather forecast predict for the weekend?"
]
def main():
perplexity_calculator = PerplexityCalculator()
df_perplexity = [
{'queryExpression': sentence, 'perplexity': perplexity_calculator.calculate_perplexity(sentence)}
for sentence in sentences
]
return pd.DataFrame(df_perplexity).sort_values('perplexity')
df = main()
df
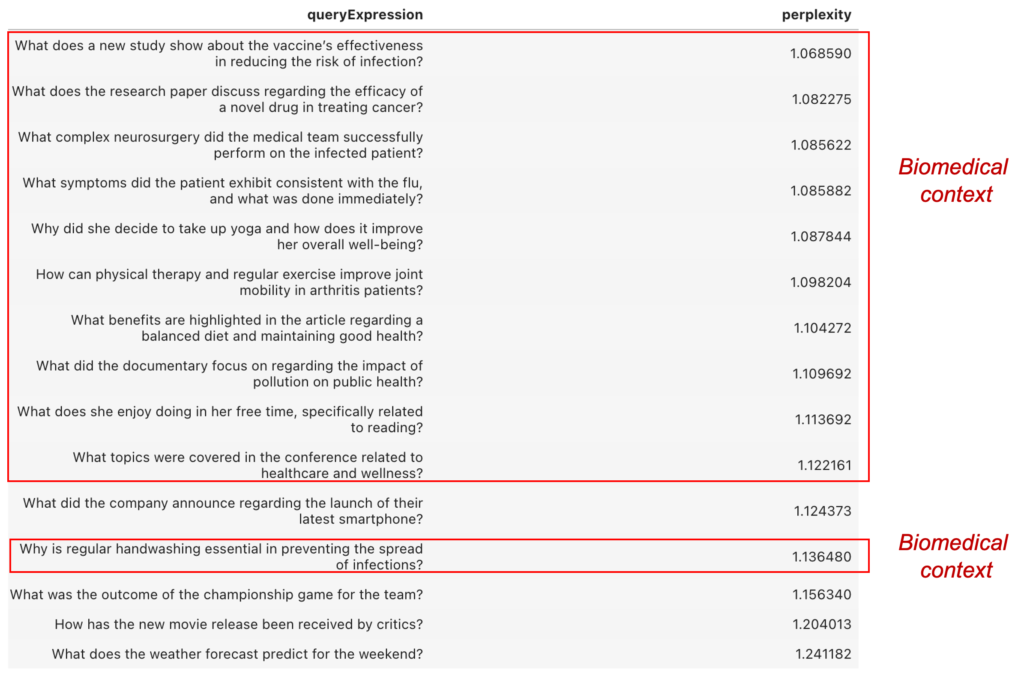
| queryExpression | perplexity | |
|---|---|---|
| 0 | What does a new study show about the vaccine’s effectiveness in reducing the risk of infection? | 1.068590 |
| 2 | What does the research paper discuss regarding the efficacy of a novel drug in treating cancer? | 1.082275 |
| 3 | What complex neurosurgery did the medical team successfully perform on the infected patient? | 1.085622 |
| 1 | What symptoms did the patient exhibit consistent with the flu, and what was done immediately? | 1.085882 |
| 6 | Why did she decide to take up yoga and how does it improve her overall well-being? | 1.087844 |
| 4 | How can physical therapy and regular exercise improve joint mobility in arthritis patients? | 1.098204 |
| 7 | What benefits are highlighted in the article regarding a balanced diet and maintaining good health? | 1.104272 |
| 9 | What did the documentary focus on regarding the impact of pollution on public health? | 1.109692 |
| 12 | What does she enjoy doing in her free time, specifically related to reading? | 1.113692 |
| 5 | What topics were covered in the conference related to healthcare and wellness? | 1.122161 |
| 13 | What did the company announce regarding the launch of their latest smartphone? | 1.124373 |
| 8 | Why is regular handwashing essential in preventing the spread of infections? | 1.136480 |
| 11 | What was the outcome of the championship game for the team? | 1.156340 |
| 10 | How has the new movie release been received by critics? | 1.204013 |
| 14 | What does the weather forecast predict for the weekend? | 1.241182 |